Based on the 28nm technology breakthrough, Xilinx has announced two industry-first products based on 20nm nodes. Xilinx is the first company to introduce a 20nm commercial chip product. In addition, the new device is the first product that Xilinx will introduce to the market with UltraScale® technology, the first ASIC-level architecture for the programmable industry. The UltraScale architecture leverages the power of cutting-edge EDA technology in the Vivado® design suite to enable customers to quickly implement a new generation of All Programmable innovations. At the 28nm node, Xilinx is the first in the industry to introduce the Zynq®-7000 All Programmable SoC and Virtex®-7 3D IC. The move will continue to maintain Xilinx's advantage over the entire generation of competitors from the 28nm process node.
Steve Glaser, senior vice president of marketing and corporate strategy at Xilinx, said: "Xilin is the first company to introduce 28nm devices. At the 20nm process node, we continue to maintain the most aggressive product launch plans in the industry. Our efforts Once again, Xilinx is far ahead of the competition for at least a year on high-end devices, and at least half a year on mid-range devices."
Like the 28nm technology node, Xilinx has also achieved some of the industry's first technological innovations in its new product portfolio. First, the company introduced a new generation of UltraScale architecture that will use 20nm, 16nm FinFET or even more advanced processes. Glaser said: "This is the industry's first programmable architecture to help users achieve ASIC-level design with All Programmable devices. The UltraScale architecture enables Xilinx's 20nm and 16nm FinFET All Programmable to provide massive I/O and memory bandwidth. Fastest packet processing and DSP processing, ASIC-like clocking, power management and multi-level security."
Architectural advantage
The UltraScale architecture includes hundreds of architectural improvements, but many of these improvements are not possible without the Vivado design suite. The Vivado Design Suite provides Xilinx customers with advanced EDA tooling capabilities, such as Vivado's advanced place-and-route capabilities that help users get the most out of UltraScale's massive data processing capabilities, enabling design teams to increase UltraScale utilization to over 90% And can meet stringent performance and power requirements. Such high utilization greatly exceeds the level that competing products can achieve. Competing products now require users to sacrifice performance to improve utilization, which makes customers have to choose larger and more expensive devices, and they find that they find The clock rate needs to be slowed down to meet system power requirements.
At the 28nm process node, this problem no longer exists, thanks to Xilinx's cabling architecture. This does not pose a problem at the 20nm process node because the UltraScale architecture enables massive data streams for wide buses to help customers develop systems with multiple Tb throughput and lowest latency. The UltraScale architecture, optimized in conjunction with Vivado, eliminates bottlenecks in DSP and packet processing by cascading high-optimized critical paths with built-in high-speed memory. The enhanced DSP subsystem combines critical path optimization with a new 27-bit 18-bit multiplier and two adders to significantly improve the performance and efficiency of fixed-point and IEEE-754 floating-point operations. The wide memory implementation also works with UltraScale 3D ICs, significantly improving inter-wafer bandwidth for improved overall performance.
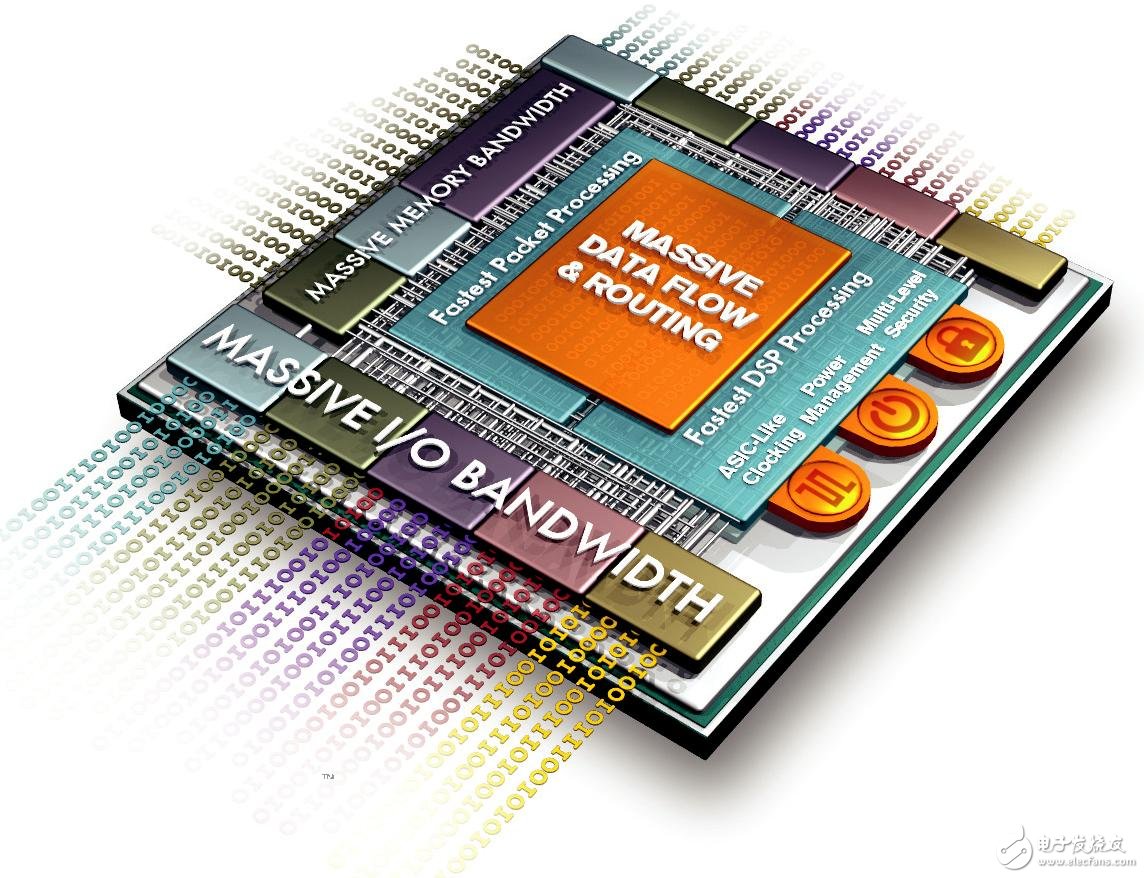
Figure 1 – The UltraScale architecture provides massive I/O and memory bandwidth, supporting the fastest packet processing and DSP processing, ASIC-like clocking, power management, and multi-level security.
Multi-zone clocking technology, often found only in ASIC-class products, enables designers to build high-performance, low-power, clock skewed clock networks in their systems.
UltraScale devices have further improved I/O and memory bandwidth, including support for next-generation memory connections, dramatically reducing latency and optimizing I/O performance. The architecture provides multiple hardened ASIC-level IP cores including 10/100G Ethernet, Interlaken and PCIe®.
The UltraScale architecture also supports multi-region clocks, which are typically found only in ASIC-class products. Multi-zone clocks enable designers to build high-performance, low-power, low-clock skew clock networks in their systems. The UltraScale architecture and Vivado's collaborative optimization also enable the design team to further reduce power consumption by enabling more power gating techniques for more of the different functional components of the Xilinx 20nm All Programmable product.
Last but not least, UltraScale also supports advanced methods such as AES bitstream decryption and authentication, key obfuscation, and secure device programming to achieve industry-leading system security.
Tailored to specific key markets
Glaser pointed out that the design team can use UltraScale devices to achieve higher system integration while maximizing overall system performance, reducing overall system power consumption and total bill of materials costs for the system. “The FPGA was only considered a good replacement for logic devices, but Xilinx continues to use the 20nm and FinFET 16/14 processes to enhance All Programmable technology based on the results achieved at its 28nm process node,†he said. The value has made it far beyond the value expectations of FPGA products. Our unique system value has been highlighted in many different applications."
Glaser pointed out that devices using the Xilinx 20nm and 16nm FinFET UltraScale architecture can meet the needs of a variety of emerging market segments such as optical transport networks (OTN), network high performance computing, digital video and wireless communications (see figure). 2). All of these areas must meet increasing demands for product performance, cost, low power consumption, and large-scale integration.
Figure 2 – The UltraScale architecture will accelerate the development of next-generation systems of different types, especially in the areas of wired and wireless communications.
Specifications
| Counting speed | ≦1500pcs/min(For coins with a diameter of 25mm) |
| Diameter | 14-34.0mm |
| Thickness | 0.8-3.8mm |
| Hopper capacity | 4000pcs |
| Packing/wrapping speed | ≦15packages/min(For coins with a diameter of 25mm.) |
| Package way | Hot iron |
| Packing bag size | Length:100-140mm, Width:100mm |
| Operation interface | HMI |
| Driving mode | Electric |
| Power requirements | AC 220-240V 50Hz |
| Current | AC 6A |
| Power consumption | 1.2KW |
| Noise | < 70dB |
| Control system |
PLC XC5-32T-E/C |
pack coins into small plastic bag,Coin Sachet Machine,Coin bagging
Suzhou Ribao Technology Co. Ltd. , https://www.ribaoeurope.com