The current machine translation model is based on the encoder-decoder system structure. This article proposes a new translation model called "universal attention", which uses 2D convolutional networks for sequence prediction, and the translation results of long sentences and short sentences are better. Well, there are fewer parameters used. Experiments show that the overall performance of the new model is better than the current best decoder-encoder model system.
At present, the most advanced machine translation system is based on the encoder-decoder architecture, which first encodes the input sequence, and then generates the output sequence according to the input code. Both are related to the attention mechanism interface, which recombines the fixed encoding of the source token based on the decoder state.
This article proposes an alternative method for a single 2D convolutional neural network spanning two sequences. Each layer of the network re-encodes the source token according to the current output sequence. Therefore, attention-like attributes are common throughout the network. Our model performed well in the experiment and outperformed the most advanced encoder-decoder system at present, while being simpler in concept and with fewer parameters.

"Universal Attention" Model and Principle
The convolutional layer in our model uses an implicit 3×3 filter, and the features are only calculated based on the previous output symbols. The picture shows the receptive field after one-layer (dark blue) and two-layer (light blue) calculations, and the hidden part of the field of view with a normal 3×3 filter (gray).
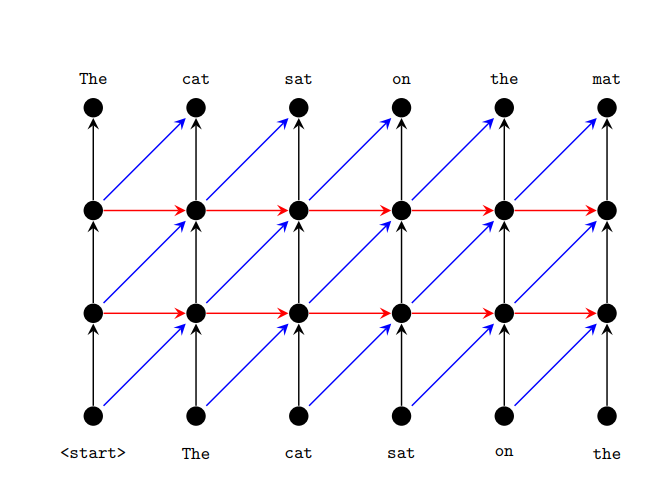
The figure above is a diagram of the decoder network topology with two hidden layers. The nodes at the bottom and the top represent the input and output respectively. Horizontal connection is used for RNN, and diagonal connection is used for convolutional network. In both cases, vertical connections are used. Parameters are shared across time steps (horizontal direction), but not across layers (vertical direction).
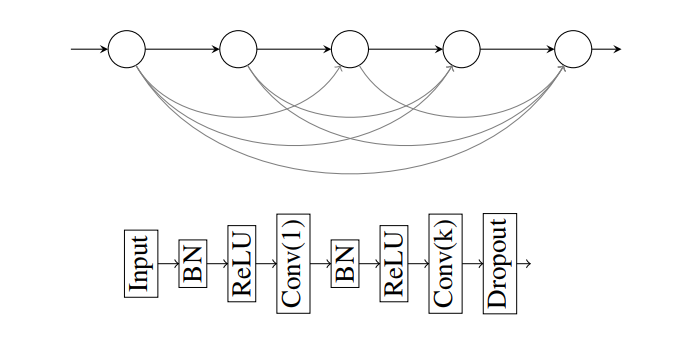
DenseNet architecture at the block level (top) and within each block (bottom)
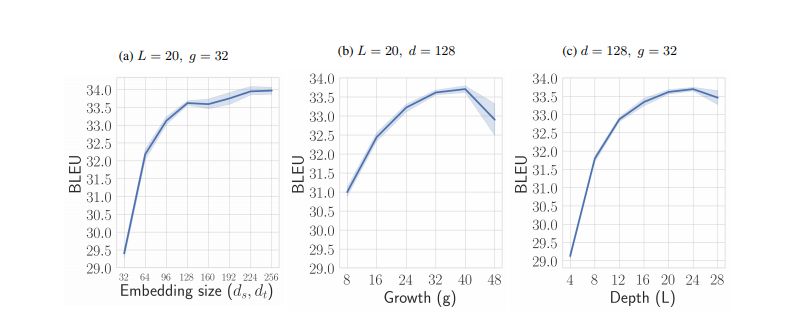
Influence of token embedding size, number of layers (L) and growth rate (g)
Whether it’s a long sentence or a short sentence, the translation result is better
Comparison with the best available technology
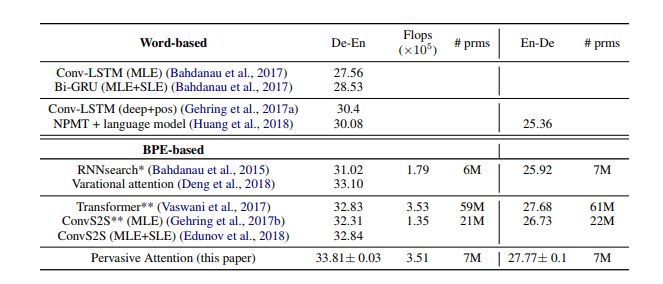
We compared the results with the existing technologies in Table 3, including German-English translation (De-En) and English-German translation (En-De). Our model is called Pervasive Attention. Unless otherwise stated, we use Maximum Likelihood Estimation (MLE) to train the parameters of all models. For some models, we will additionally report the results obtained through sequence level estimation (SLE, such as reinforcement learning methods). We usually aim directly at optimizing the BLEU measurement, rather than the probability of correct translation.
Performance on different sentence sequence lengths
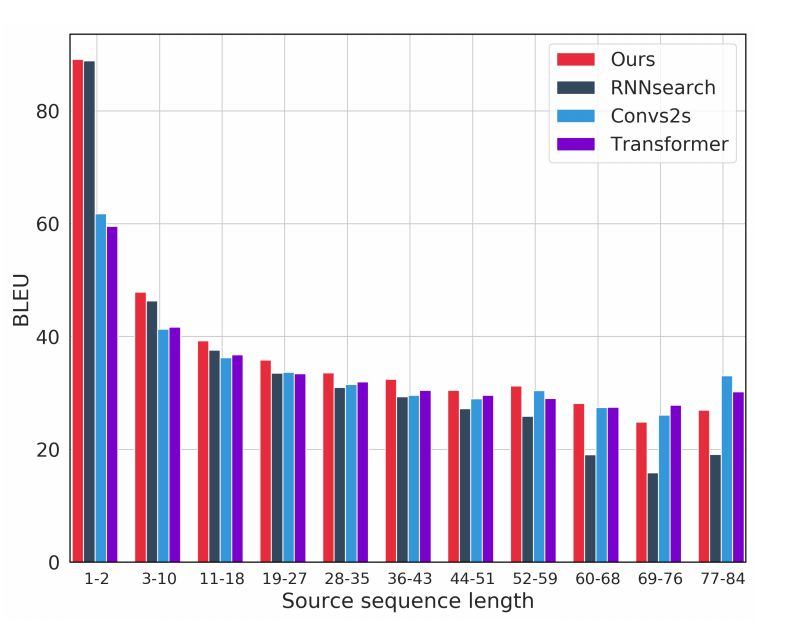
In the figure above, we treat translation quality as a function of sentence length and compare our model with RNNsearch, ConvS2S, and Transformer. The results show that our model obtains the best results on almost all sentence lengths, and ConvS2S and Transformer only perform better on the longest sentences. In general, our model combines the strong performance of RNNsearch in short sentences, and it is also close to the good performance of ConvS2S and Transformer on longer sentences.
Implicit sentence alignment
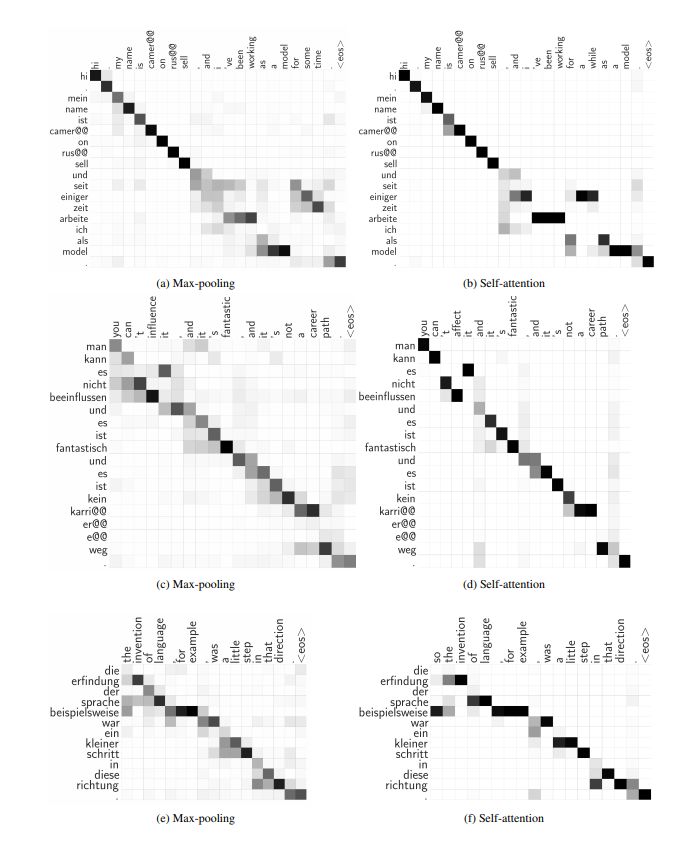
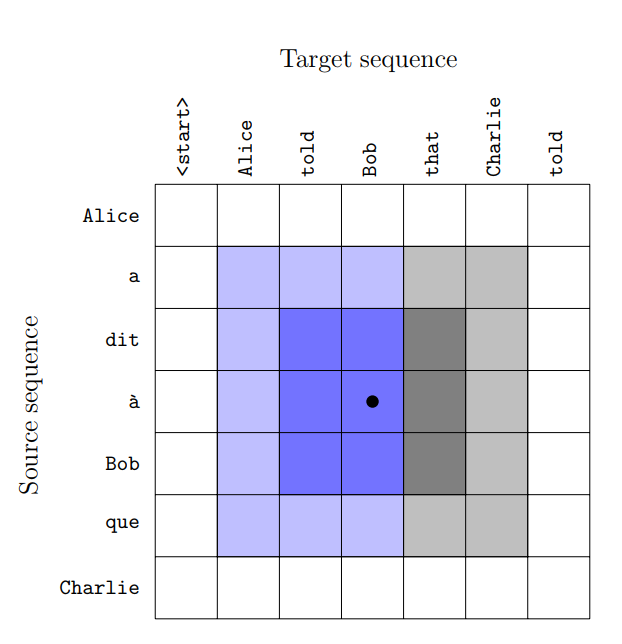
The figure above shows the implicit sentence alignment generated by the max pooling operator in our model. For reference, we also show the alignment produced by the "self-attention" used by our model. It can be seen that both models have successfully simulated implicit sentence alignment qualitatively.
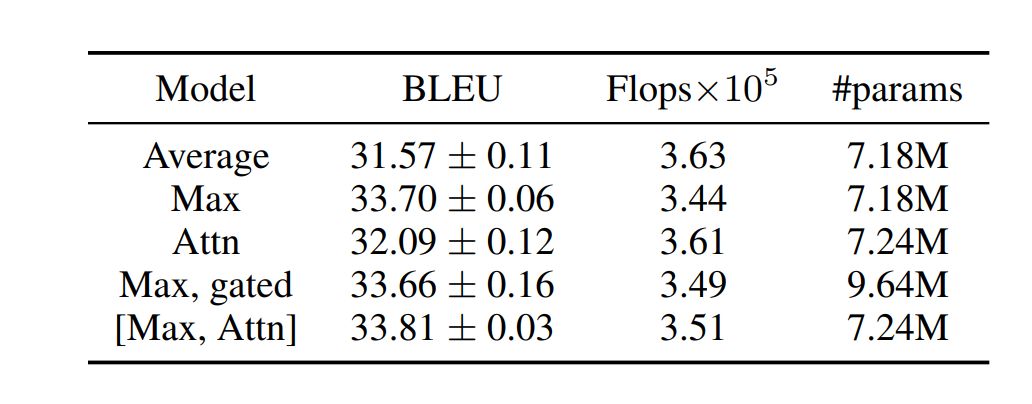
Our model (L = 24, g = 32, ds = dt = 128), with different pooling operators, uses a gated convolution unit
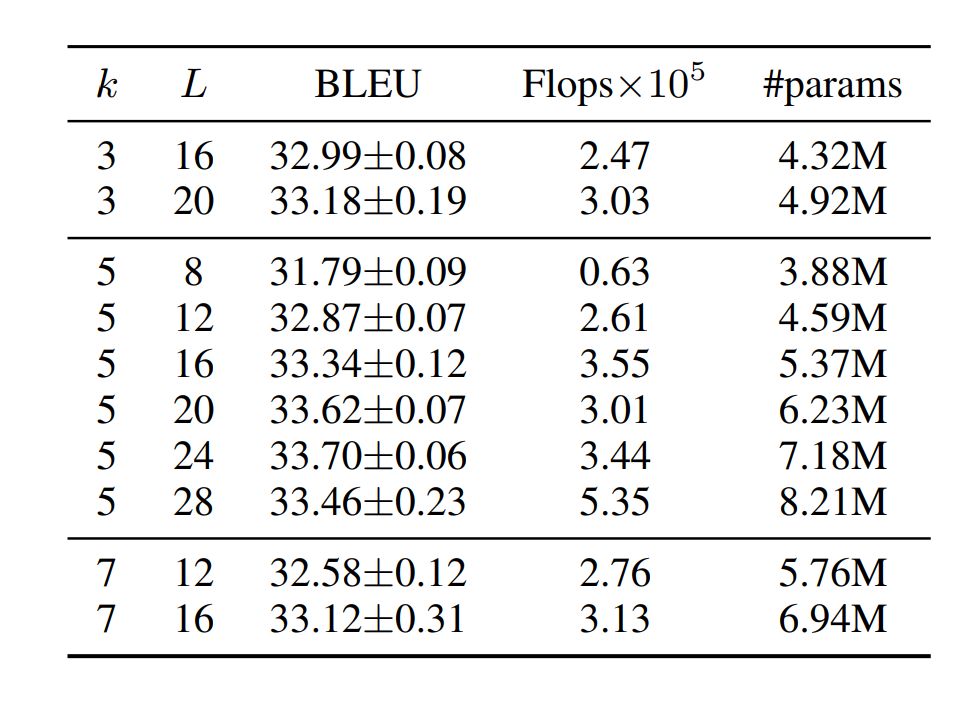
Under different filter size k and depth L, the performance of our model (g = 32, ds = dt = 128).
Comparison with the latest results of the IWSLT German-English translation model.
(*): Results obtained using our implementation (**): Results obtained using FairSeq.
Break away from the encoder-decoder paradigm and use DenseNet for machine translation
We propose a new neural machine translation architecture that breaks away from the encoder-decoder paradigm. Our model jointly encodes the source sequence and the target sequence into a deep feature hierarchy, where the source token is embedded in the context of part of the target sequence. This joint coding is maximally pooled along the source dimension, and the relevant elements are mapped to the prediction of the next target token. This model implements 2D CNN based on DenseNet.
Since our model combines context and re-encodes the input tokens of the target sequence currently generated in each layer, each layer of the network structure of the model has "attention-like" attributes.
Therefore, adding a clear "self-attention module" has a very limited but very positive effect. However, the implicit sentence alignment generated by the maximum pooling operator in our model is similar in nature to the alignment generated by the attention mechanism. We evaluated our model on the IWSLT'14 dataset, translating German-English bilingually.
The BLEU score we obtained is comparable to the existing best method. Our model uses fewer parameters and is conceptually simpler. We hope that this achievement can spark interest in alternatives to the encoder-decoder model. In the future, we plan to study hybrid methods, where the input of the joint coding model is not provided by the embedding vector, but the output of the 1D source and target embedding network.
In the future, we will also study how this model can be translated across multiple languages.
2 In 1 Laptop
Do you know the difference of Yoga Laptop and 2 in 1 laptop? No. 1 is yoga notebook with 360 flip rotating absolutely; No.2 is laptop yoga slim is just like normal Education Laptop-connecting screen with keyboard, but 2 in 1 laptop tablet with pen is separately, you can use the monitor part as a window tablet. In one word, every intel yoga laptop have all the features and function of tablet 2 in 1 laptop except separated screen and keyboard. From the cost, windows yoga laptop is much higher than 2 in 1 type., cause usually former with more complicated craft and quality.
What other products you mainly produce? It`s education laptop, Gaming Laptop, engineering laptop, Android Tablet, Mini PC and All In One PC. You can see more than 5 different designs on each series, believe always have right one meet your special application or your clients demands. Therefore, what you need to do is just to get all the requirement details from your clients, then share the complete information with us, then we can provide the most suitable situation.
Of course, you can also call or email or send inquiry of what you need, thus can get value information much quickly.
2 In 1 Laptop,2 In 1 Laptop Sale,2 In 1 Laptop Tablet With Pen,Tablet 2 In 1 Laptop,2 In 1 Laptop Deals
Henan Shuyi Electronics Co., Ltd. , https://www.shuyiaiopc.com